理解樣本變異數與自由度(二):樣本變異數校正
上一章:第一章
上一章我們淺談了自由度的概念,但還有一個十分核心的問題沒有解決:就算在公式當中加入樣本平均值會讓我損失一個自由度,憑什麼我的分母的樣本數就得要減一?如果我堅持使用樣本數會怎麼樣嗎?
如果要一句話給出我的答案:會,使用樣本數作為分母會讓你錯誤估計母體的變異數,更精確來說,會低估母體的變異數。其中的原因正是因為我們在公式當中使用了樣本平均值(\(\bar{x}\))而非母體平均值(\(\mu\))。
用統計的語言來說,樣本變異數的分母必須是 n-1,才會是母體變異數的不偏估計式(unbiased estimator),但這個下一章再談。
直覺了解使用樣本平均值的影響
我們都知道樣本變異數在衡量數據間離散程度,也就是樣本彼此的距離有多遠。更進一步來說,我們測量的方法,是計算每個樣本「平均而言」跟樣本平均值的距離有多遠。讓我們再看一次樣本變異數的公式:
\[S^{2} = \frac{1}{n-1}\sum_{i = 1}^{n} (x_{i} - \bar{x})^{2}\]放心,這裡不會有任何的真正數學計算出現,因此或許以下解釋聽起來會有點不牢靠,但希望你可以跟我一起進行一場思想實驗:
假設我們現在有兩筆數據,它們的平均值正好坐落在真正的母體平均值上(當然我們不知道母體平均值是什麼)。
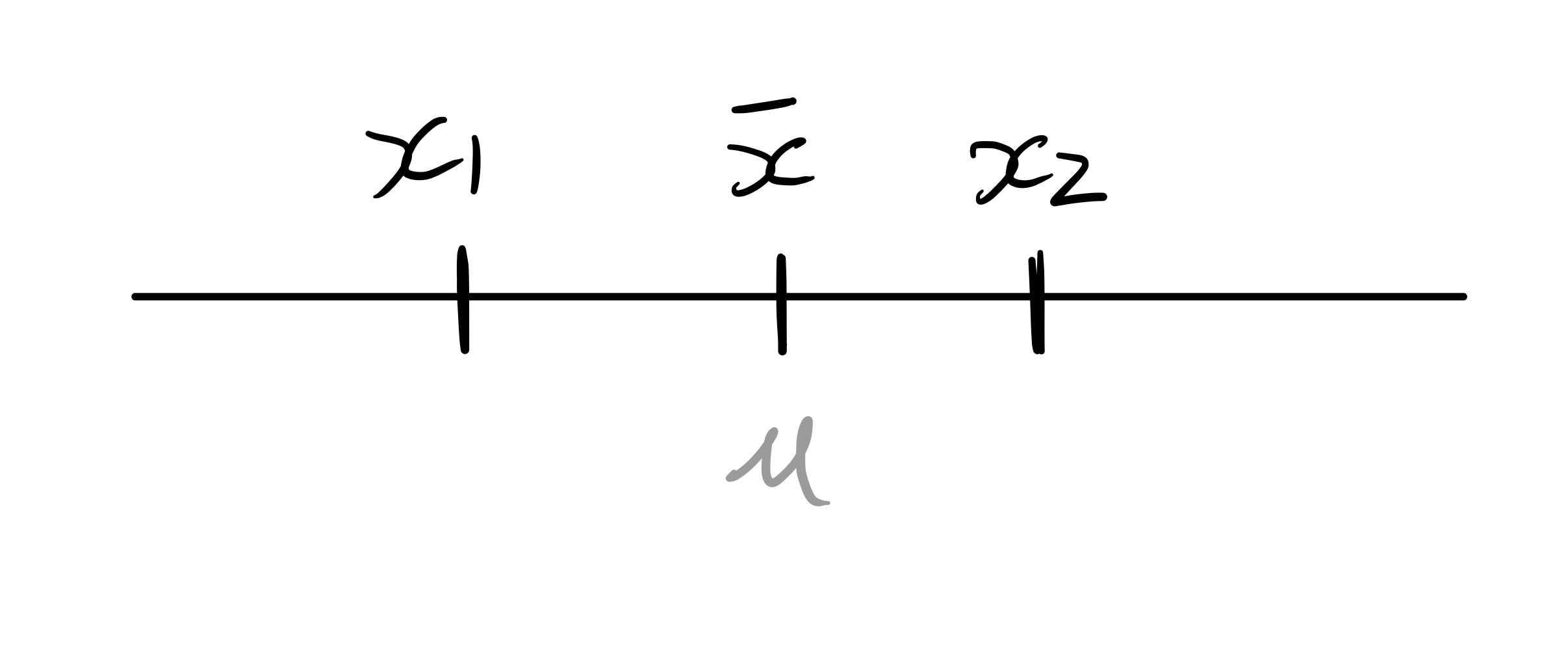
現在我們抽出了第三筆數據,它跟其他兩筆數據相隔非常遠。這時我們會發現,母體平均值文風不動地待在原地,但樣本平均值卻因為這筆很大的數值被「拖」向右邊!也就是說,樣本平均值離第三筆數據更靠近了。
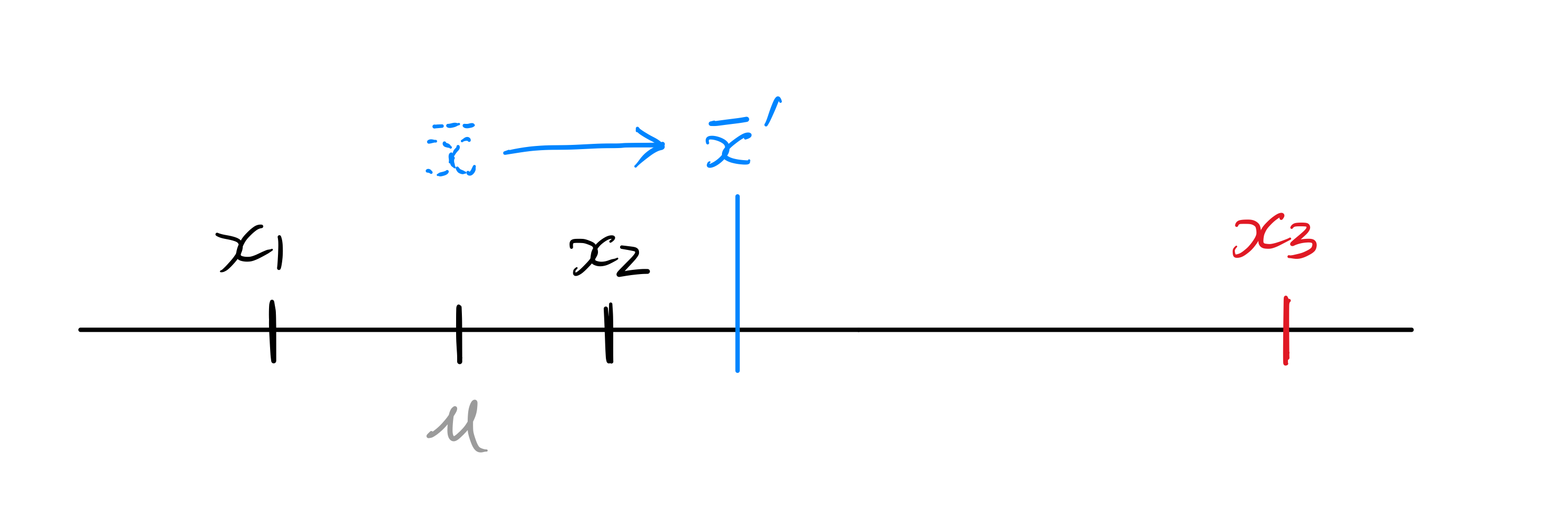
這時的你應該已經看出一些端倪了。我們發現樣本平均值在面臨新的數據來臨時,是多麽地不可靠。樣本平均值會乖乖移動到現有數據的中心(不能怪它,平均值本來就是這樣運作的)。現在如果我們以母體平均值作為中心點來看,\(x_{3}\) 是一個遠得誇張的點,因此整個樣本的離散程度很大。然而,從樣本平均值作為中心來看,因為兩邊更對稱,沒有極端值,數據好像更集中了一點。
這是一個非常非常不精準的說法,有很多的數學跟邏輯漏洞,但我只是希望能用一個更直覺的方式讓你理解它。)
在這裡,我們想透過「與平均值的平均距離」來衡量變異數,但我們的平均值卻又是透過樣本自己定義的(而非真正的母體平均值)?這種球員兼裁判的計算方式,當然會有利於降低樣本的變異數,讓數據看起來更集中。因此,在採用 \(\bar{x}\) 作為中心點的變異數計算中,我們其實受到樣本字體的的影響,低估了真正的變異數。
這樣的錯誤要如何校正呢?其實只要把我低估的部分放大回去就可以了。眾所周知,一個分數分子如果固定不變,分母越小,分數越大。所以我們只要把分母從 n 縮小成 n-1,就完成原先低估的校正了。這也是為什麼我們計算樣本變異數的時候,分母必須是 n-1 的原因:它可以避免讓我們低估母體變異數。
這時會有一個問題很自然的浮現:我知道要校正,但為什麼是改成 n-1?不是 n-2 或 n-0.5?這個「低估的程度」是怎麼計算出來的?
這個問題就需要用上一些理論和數學計算來解釋了,我們將會在下一章仔細地推導。
樣本數夠大,用 n 或 n-1 都可以?
直覺上我們可以想像,當我們今天的樣本數越來越多時,每一個數據對樣本平均值的影響就會越小(越來越「拖」不動),也就是說,樣本平均值在有大量數據時,也不太會因為新的數據而有極端的變動了。而且,樣本數越大,代表我們樣本平均值會越來越靠近母體平均值(換個方式說,我們對母體平均值的估計越來越準確)。兩個因素結合起來,我們發現在樣本數非常大的時候,其實樣本變異數低估的程度也會慢慢地減少,對於真正母體變異數的估計也會跟著越來越好。
回到公式上來看,我們也會發現當 n 變得非常非常大的時候 \(1/n\) 和 \(1/(n-1)\) 的差異其實也變得越來越不顯眼,這時就算分母不使用 n-1 而改用 n,也不會有很大的誤差了。這也是為什麼許多老師會在高中時和我們說,當樣本數夠大的時候,用 n 或 n-1 沒有很大差異的原因。而這點也會在後面的證明中更嚴謹地定義一次。
用另一個角度看樣本變異數的自由度
以下這個是一個不必然精確,但我覺得另一個十分容易理解為何在處理樣本自由度時,分母是 n-1 的解釋。
我們可以想像在計算樣本變異數時,我們同樣意義上,其實是在計算每個相鄰數據間的距離平均值(其實並不是,但 bear with me)。如果每兩兩相鄰數據的平均距離越大,我們可以想像樣本的分佈本身也會更稀疏、更離散(想想全距的概念)。那要如何計算兩兩相鄰數據的距離的平均值呢?很直覺地我們可以將所有相鄰樣本的距離加總,並且除以我們用了幾個距離的數據。而 n 筆數據間會有幾個兩兩相鄰的距離呢?正是 n-1 個!(用更生活化的例子來形容,人行道上的三棵樹,兩兩平均距離是總距離除以二,因為三棵樹之間只有兩個相鄰距離)。
一言以蔽之,既然樣本變異數求取的是數據間的平均距離,而 n 個數據點能給我們 n-1 筆距離數據,樣本變異數的分母很自然的就得要是 n-1。
回到自由度的定義上,我們也可以說,如果我們已經獲取每一筆(也就是 n-1 筆)兩兩相鄰距離的數據了,在剩下最後一筆數據時(我們假設它必須出現在樣本最右方),這筆數據是不是也已經沒有選擇自己能去哪的自由了?這時我們便失去了一個自由度,因為 n-1 筆距離數據正是用 n 筆數據推算出來的。
這時反應快的你可能已經會產生幾個問題了。第一,既然我們要計算平均距離,為什麼不需要考量非兩兩相鄰的數據點之間的距離,一起納入平均?(也就是說,\(x_{1}\)、\(x_{2}\)、\(x_{3}\) 由左到右一字排開,為什麼只考量 \(x_{1}, x_{2}\) 之間,和 \(x_{2}, x_{3}\) 之間的距離,卻不考慮 \(x_{1}\) 和 \(x_{3}\) 之間的距離?)而答案是,我們其實已經考量到了。所有非兩兩相鄰數據點之間的距離,都可以用它們之間所有兩兩相鄰數據的距離加總而成(也就是說,\(x_{1}, x_{3}\) 之間的距離就是 \(x_{1}, x_{2}\) 和 \(x_{2}, x_{3}\) 之間的距離加總)。所以,這些非兩兩相鄰相鄰的數據點之間的距離也是「不自由」的。
第二,那為何母體變異數就可以除以 n 而非 n-1?這是因為在母體變異數的計算中,我們算的不是兩兩相鄰數據點間的平均距離,而是所有數據與「母體平均值」之間的距離,因此每個數據都與母體平均值有一筆自己的距離,n 筆數據自然就會產生 n 個距離,因此要除以 n。回頭來想想,樣本變異數的計算方式是與「樣本平均值」之間的平均距離,但如上所述,樣本平均值正是由樣本自己所定義的!所以計算與樣本平均值間的平均距離,本質上就是在計算樣本中的數據點互相的平均距離。樣本平均值是我們自己用樣本造出來的點,不能單獨當作一個獨立可靠的數據點來看!
再次強調,以上的直覺思考在數學上是非常鬆散的寫法(對距離的定義、兩兩相鄰距離不同於變異數),但我想在直觀意義上,這是非常快速可以抓住自由度概念的一種思考模式。
結論
以上就是用直覺方式思考自由度,以及樣本變異數的分母為何是 n-1 的邏輯。我知道這邊文章又臭又長,可能還有很多邏輯詭怪,甚至看不懂的地方。如果有任何地方無法理解,很大機率是我沒有把文章寫好的問題,歡迎留言或聯絡我,我會儘速回覆並修正文章。
之後就是比較技術性的內容了,適合對統計有點底子,想用更數學的方法清楚理解樣本變異數的你。如果你只是單純好奇或苦惱,在網路上找不到自由度或樣本變異數的科普文章,希望看到這裡可以解決你的一點好奇心。
下一章讓我們用更嚴謹的方式,理解使用樣本平均值 \(\bar{x}\) 計算變異數造成的偏誤,以及修正的幅度。
文章總結
- 計算樣本變異數時,使用 n 而非 n-1 會讓你低估樣本的變異程度
- 其中的原因正是因為我們用上了樣本平均值,而這個平均值是用樣本自己定義出來的
- 將 n 修正為 n-1 後,會將計算的結果放大,並且準確估計母體變異數
- 另一個角度來看,我們可以將樣本變異數理解為「樣本間的平均距離」
- 因為 n 筆數據只會有 n-1 筆相鄰距離,所以計算平均距離時要除以 n-1
下一章:第三章