SQL 的 INNER/LEFT/RIGHT/FULL JOIN
最近在複習 SQL 的 JOIN 子句,來來回回寫了 SQL Zoo、SQL Teaching 和 SQL Bolt 的好多題目後,對各種 JOIN Clause 有了更深一層的了解,因此想記錄下來作為未來的參考。另外,關於 SELF JOIN 的討論會放在下一篇文章。
INNER/LEFT/RIGHT/FULL JOIN
在這四種 JOIN 裡面或許最常用的(也或許是裡面最直覺的)就是 INNER JOIN,不過因為這四個的關係其實密不可分,因此我認為放在一起整理是最有幫助的。
在想像兩個 table 做 JOIN 時,我覺得最好的 mental model 就是用文氏圖思考:
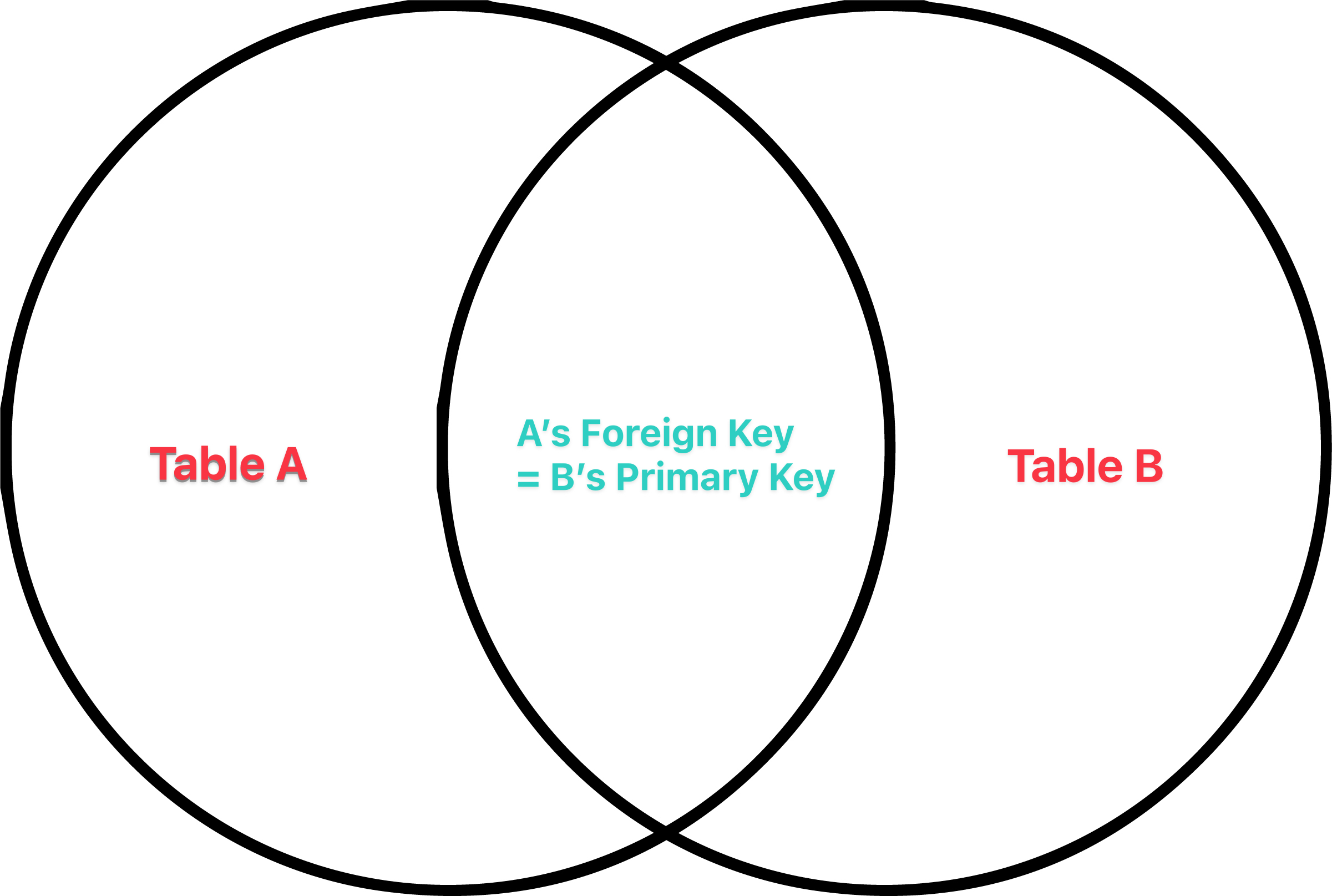
JOIN 背後的運算就是將兩個 table 串接起來,而串接的「節點」就是 A 的 Foreign Key 和 B 的 Primary Key(雖然也不必然是用 key 串接,但為方便解說先暫假設如此)。以下方的資料庫為例,我們創建一個「教授」表格和一個「系所」表格(我附上完整的資料庫創造指令,可以用 SQlize 或類似網頁、程式執行):
CREATE TABLE prof (
id INT,
name VARCHAR(50),
deptid INT,
PRIMARY KEY(id)
);
CREATE TABLE dept (
id INT,
name VARCHAR(50),
PRIMARY KEY(id)
);
INSERT INTO prof
VALUES
(1, 'William', 10),
(2, 'Nina', 20),
(3, 'Lee', 20),
(4, 'Kevin', NULL);
INSERT INTO dept
VALUES
(10, 'Physics'),
(20, 'Chemistry'),
(30, 'Arts');
先稍微看一下資料庫的結構:
SELECT * FROM prof;
--|----|---------|--------|
--| id | name | deptid |
--|----|---------|--------|
--| 1 | William | 10 |
--| 2 | Nina | 20 |
--| 3 | Lee | 20 |
--| 4 | Kevin | [null] |
SELECT * FROM dept;
--|----|-----------|
--| id | name |
--|----|-----------|
--| 10 | Physics |
--| 20 | Chemistry |
--| 30 | Arts |
我們發現 prof 中的 deptid 可以和 dept 中的 id 連結,將這兩張表串接成一張表。不過 dept 當中有人沒有系所資料(Kevin),且 dept 中也有一個系所(Arts)沒有任何 prof 中的教授。這時一個問題就會在串接的過程中自然形成:
無法串接的資料要如何處理?
INNER JOIN
INNER JOIN 的處理方式很直接,只要無法串接的資料全部丟棄。因此上面的兩個表單若透過 INNER JOIN 串接,prof 中的 Kevin 和 dept 中的 Arts 就會直接不見:
SELECT *
FROM prof INNER JOIN dept ON prof.deptid = dept.id;
--|----|---------|--------|----|-----------|
--| id | name | deptid | id | name |
--|----|---------|--------|----|-----------|
--| 1 | William | 10 | 10 | Physics |
--| 2 | Nina | 20 | 20 | Chemistry |
--| 3 | Lee | 20 | 20 | Chemistry |
用文氏圖表示的話,就是只有中間的交集部分有被顯示出來:
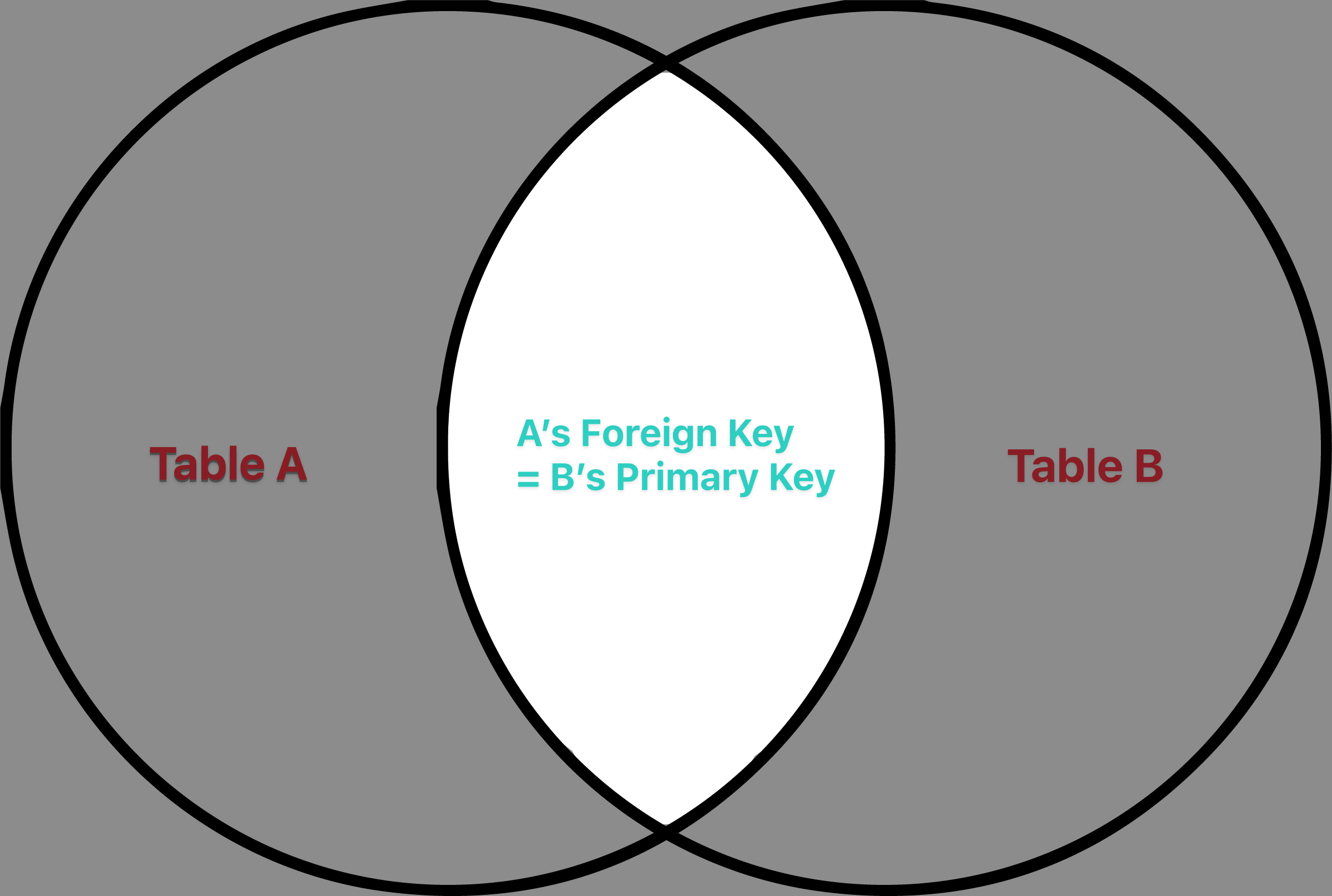
INNER JOIN 十分適合用在我們不在意無法配對的 entry 的時候(也就是大部分時候)。
LEFT/RIGHT JOIN
LEFT JOIN 和 RIGHT JOIN 對於無法配對的 entry 處理的態度一樣:只保留其中一邊。他們唯一的差別在於 LEFT JOIN 選擇保留子句左邊的 entry,而 RIGHT JOIN 只保留子句右邊的 entry。並且在串接後的空白處補上空值 NULL(注意不會補上 DEFAULT 值)。沿用上面的資料庫:
SELECT *
FROM prof LEFT JOIN dept ON prof.deptid = dept.id;
--|----|---------|--------|--------|-----------|
--| id | name | deptid | id | name |
--|----|---------|--------|--------|-----------|
--| 1 | William | 10 | 10 | Physics |
--| 2 | Nina | 20 | 20 | Chemistry |
--| 3 | Lee | 20 | 20 | Chemistry |
--| 4 | Kevin | [null] | [null] | [null] |
SELECT *
FROM prof RIGHT JOIN dept ON prof.deptid = dept.id;
--|--------|---------|--------|----|-----------|
--| id | name | deptid | id | name |
--|--------|---------|--------|----|-----------|
--| 1 | William | 10 | 10 | Physics |
--| 3 | Lee | 20 | 20 | Chemistry |
--| 2 | Nina | 20 | 20 | Chemistry |
--| [null] | [null] | [null] | 30 | Arts |
我們發現在 LEFT JOIN 的情況下,左邊的 prof 表格中的 Kevin 被保留了下來,不過卻因為沒有對應的 deptid,因此串接後的表格,Kevin 後面跟了一連串的空值。另外,右邊的表格 dept 中的 Arts 直接在組合後的表格中消失了。
這件事情在 RIGHT JOIN 的情況下相反:Arts 被保留下來,串接後無法配對的空間被補上 NULL,且 Kevin 不見了。
LEFT JOIN 的情況,用文氏圖類比的話就會呈現下圖的狀態:
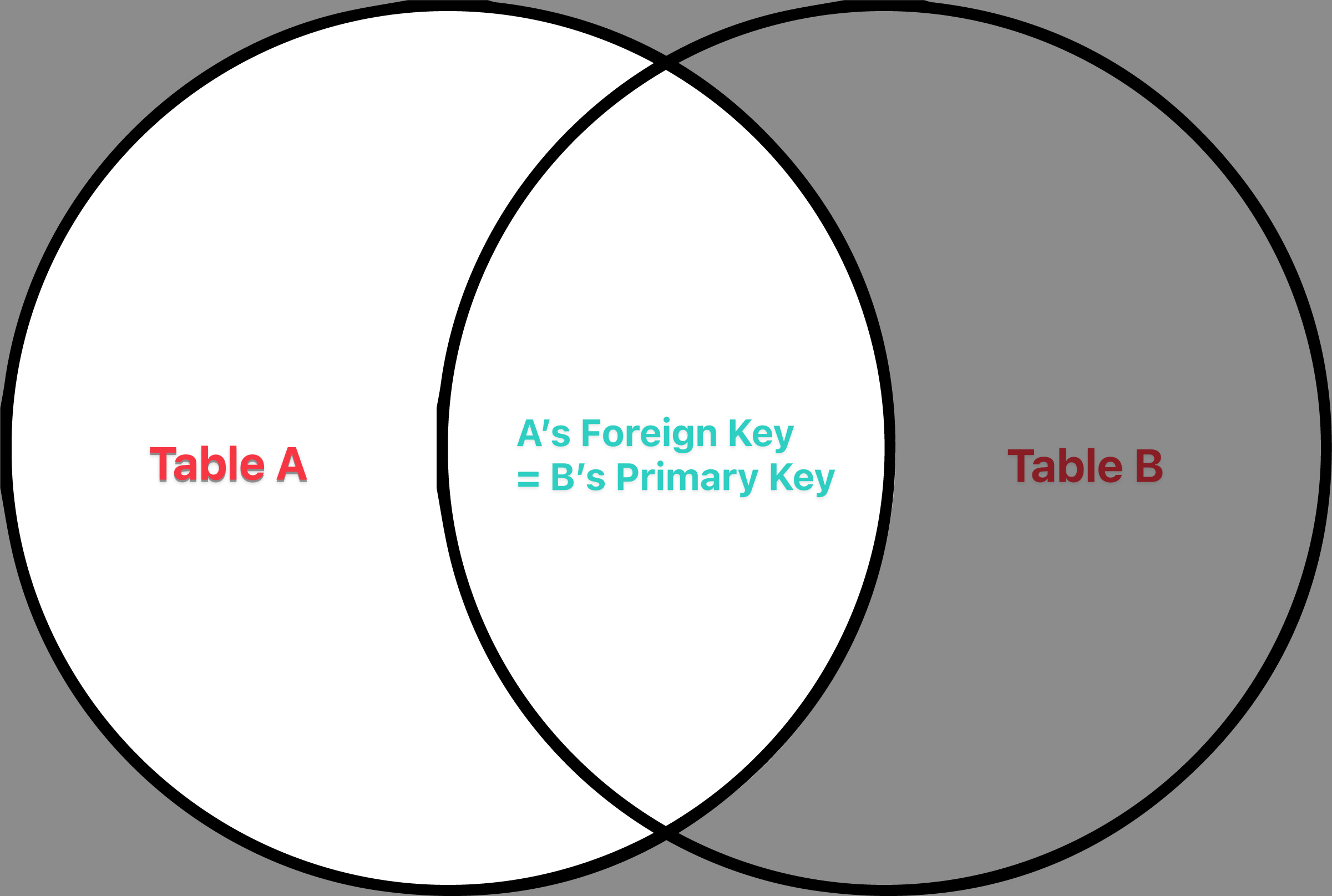
也就是 Table A 的所有資料都留存,但如果 B 中有資料無法跟 A 串接的話,該資料就會直接被捨棄。相當於取集合 \(A \setminus B\)。而 RIGHT JOIN 的圖就是相反,我就不畫出來了。
LEFT JOIN 因此很適合用在確保左邊的表格不能有資料丟失的情況下。例如我們想要清點學校教授人數,此時 INNER JOIN 就不適合,因為若有教授沒有 deptid,或他的 deptid 沒有對應的名稱,該教授的資料就會完全被丟棄。此時用 LEFT JOIN 就可以確保我們保有全部教授的資料,即便無法顯示系所名稱也沒關係。
FULL JOIN
最後的 FULL JOIN 的邏輯就很明顯了:我們希望保全兩邊所有資料,就算無法串接也沒關係,無法串接的空格就用 NULL 填充(註:某些 SQL Server 不支援 FULL JOIN)。
SELECT *
FROM prof FULL JOIN dept ON prof.deptid = dept.id;
--|--------|---------|--------|--------|-----------|
--| id | name | deptid | id | name |
--|--------|---------|--------|--------|-----------|
--| 1 | William | 10 | 10 | Physics |
--| 2 | Nina | 20 | 20 | Chemistry |
--| 3 | Lee | 20 | 20 | Chemistry |
--| 4 | Kevin | [null] | [null] | [null] |
--| [null] | [null] | [null] | 30 | Arts |
用文氏圖來表示就會如下圖:
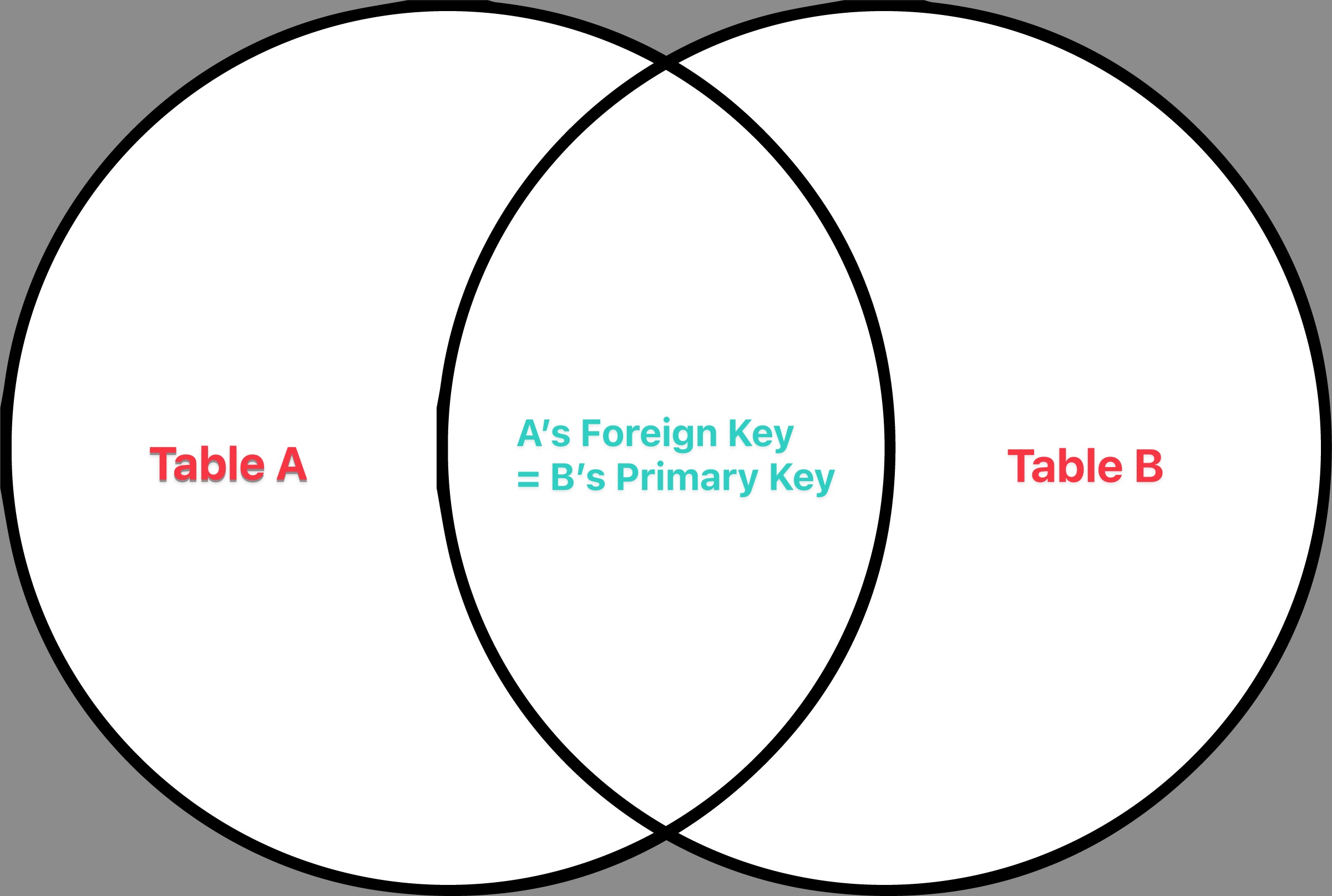
這就相當於取兩個 table 的聯集(union),寫成集合表示法就是 \(A \cup B\)。
使用 FULL JOIN 可以避免我們漏掉任何 table 中的重要資訊,但也意味著我們可能會產生出許多的 NULL,在做某些 aggregation 運算時(如 SUM())需要特別小心。
結論
SQL 的 JOIN 系列就是這樣看了會懂,久了又會反覆忘記的知識,剛好這次讀出點心得,想透過淺顯易懂的解釋幫助有需要的人,也幫助未來再次忘記的自己。先感謝你把文章讀到這邊,如果你有興趣,我還寫了關於 SELF JOIN 有趣應用的文章,歡迎過去看看。